통계학의 기본 개념
통계학이란 관심 대상에 대하여 관련된 자료를 수집하고 그 자료를 요약정리하여 이로부터 불확실한 사실에 대한 결론이나 일반적인 규칙성을 끌어내는 방법을 연구하는 학문이다.
통계학의 역할은 ①데이터의 수집 → ②데이터의 요약 → ③데이터로부터의 결론이다.
통계학의 연구 분야는 기술 통계학과 추측 통계학으로 구분할 수 있습니다.
기술 통계학(Descriptive Statistics)
자료를 그래프나 숫자 등으로 요약하는 통계적 행위 및 관련 방법을 기술 통계라고 한다. 기술통계는 데이터를 요약하고 시각화해서 잘 설명하는 것에 중점을 두며 데이터에 대해서 쉽게 설명하기 위해서 시각화를 많이 활용한다.
평균, 분산, 표준편차 등을 구하거나 도수분포표 히스토그램 등으로 자료를 요약하고 특징을 파악하는 연구 분야이다.
추측 통계학(Inferential Statistics)
관심 대상 전체인 모집단의 일부 즉 표본을 분석하여 모집단에 대해 추측하고 일반화된 결론을 유도하는 통계학의 연구 분야이다.
왜 일부의 자료만을 분석할까? 물리적, 경제적, 또는 시간적 제약으로 인해 일일이 전체를 조사하는 것은 불가능하다. 따라서 일부만을 조사하고 분석하여 이로부터 전체의 특성에 대해 추론하는 것이다.
이때 관심이 대상이 되는 전체를 모집단(population)이라 하고 조사된 일부를 표본(sample)이라 부른다.
통계학의 기본 용어
• 모집단(population): 관심 대상이 되는 모든 개체의 집합(전체), 보통 모집단의 특성치, 모수(parameter)는 알파벳 대신 그 모태가 되는 그리스 문자를 사용한다, 예를 들어 모평균(모집단이 평균)은 μ를 사용하고, 모 표준편차(모집단의 표준편차)는 σ를 사용한다.

• 표본(sample): 실제 조사되거나 측정되는 모집단의 일부 또는 부분 집합이다.
• 임의 추출(random sampling): 모집단의 구성요소 하나하나가 표본으로 뽑힐 확률이 같은 상황에서 표본을 뽑는 방법
• 모수(parameter): 모집단에 대한 수치 특성 값(예를 들어 모평균, 모집단의 표준 편차)으로 이들 특성 값은 모집단을 전수 조사해야만 알 수 있는 값들이다. 하지만 현실적으로 모집단을 전수 조사하는 것은 쉬운 일이 아니기 때문에 표본을 추출하여 표본의 통계량(평균, 분산, 표준편차 등)을 계산하고 표본 통계량으로 모수를 추정하여 모집단의 특성을 파악한다.
• 통계량(statistic): 표본에서 얻은 수치 특성 값(예를 들면 표본의 평균, 표준 편차)
평균(mean): 관측치의 총합을 관측치의 개수로 나누어 구한다. 중심 위치 측도로 가장 일반적으로 사용된다.
분산(variance): 평균을 중심으로 자료가 얼마나 퍼져 있는가를 나타낸다. 자료 값에서 평균값을 뺀 편차(deviation)의 제곱 값의 평균에 해당하는 값.
표준편차(standard deviation): 분산에 제곱근을 취해준 값으로 변동을 측정하는 기본 통계량이다. 분산의 제곱 값.
• 관찰 값(observation): 각 조사단위로부터 기록된 정보나 특성 값, 측정된 측정값.
• 변수(variable): 각 단위에 대해서 측정되는 특성
이산형 변수(Discrete variable)와 연속형 변수(Continuous variable)로 구분된다.
이산형 변수에는 명목 변수와 순서 변수가 있으며, 연속형 변수에는 간격 변수와 비율 변수가 있다.
1. 명목 변수(Nominal variable): 순서가 없는 범주에 해당하는 데이터
예: 성별(남, 녀), 혈액형(A, B, O, AB), 합격 여부 판정(합격, 불합격)
2. 순서 변수(Ordinal variable): 순서가 있는 범주에 해당하는 데이터
예: 학점(A, B, C, D, F), 소득 수준(상, 중, 하)
3. 간격 변수(Interval variable): 등간성이 있고, 절대 영(0)과 비율의 의미가 없는 데이터
예: 온도(온도의 0도는 인위적으로 특정 상태를 0도로 정한 것으로 기준에 따라 달라질 수 있다)
4. 비율 변수(Ratio variable): 등간성이 있고, 절대 영(0)과 비율의 의미가 있는 데이터
예: 몸무게, 키, 시간 등
실무에서 다양한 데이터를 접하다 보면 분류에 애매한 부분이 많이 있습니다. 특히 순서형 데이터와 이산 데이터의 경계가 모호한 경우가 많을 것입니다. 이럴 경우에는 데이터에 대해서 충분한 고찰 후 왜 이런 분류의 데이터로 정하였는지에 대한 합리적인(Reasonable) 판단 근거를 만드는 기준으로 삼으면 될 것입니다.
• 데이터(data): 하나 이상의 변수에 대한 관찰 값의 모음(집합)
• 특이점(이상치, outlier): 대부분의 자료가 모여 있는 군집(cluster)으로부터 멀리 떨어져 있는 자료를 말한다.
• 표본 조사 : 집단 모두를 조사하는 총조사는 비용과 시간이 많이 소요되므로 특별한 경우를 제외하고는 집단 전체가 아닌 표본을 조사하게 되는데 이러한 조사를 표본 조사라 한다.
정규 분포(Normal Distribution)
정규 분포(Normal distribution) 또는 가우스 분포(Gaussian distribution)는 연속 확률 분포의 하나이다.
정규분포는 2개의 매개 변수 평균 μ과 표준편차 σ에 대해 모양이 결정되고, 이때의 분포를 N(μ, σ2)으로 표기한다.
평균이 0이고 표준편차가 1인 정규분포 N(0, 1)을 특별히 표준 정규 분포(standard normal distribution)라고 한다.
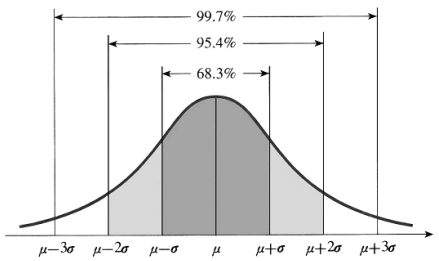
정규 분포의 성질
• 평균을 중심으로 좌우 대칭이다. (symmetric)
• 종 모양이다. (bell-shaped)
• 봉우리가 하나이다. (single-peaked)
• 평균과 표준편차에 의해서 그 모양이 결정된다.
• 분산은 같고 평균이 다를 경우 위치만 이동된다.
• 평균은 같고 분산이 다를 경우 분포의 형태만 변한다. 분산이 커질수록 퍼진다.
• 평균 = 최빈값 = 중앙값
표준화(standardization)란?
각기 다른 모양과 위치를 가지는 정규 분포를 표준 정규분포로 전환하는 방법을 표준화라고 합니다.
'유용한 정보들 > 6 시그마(Six Sigma)' 카테고리의 다른 글
| 통계적 가설 검증 방법 (0) | 2020.10.18 |
|---|---|
| 중심 극한 정리와 큰 수의 법칙(대수의 법칙) (0) | 2020.10.13 |
| 정규 분포 - 연속형 확률 변수의 분포 (0) | 2020.10.11 |
| 6 시그마(Six Sigma) 문제 해결 프로세스 DMAIC (0) | 2020.09.28 |
| 6 시그마와 3.4 ppm의 통계적 의미 (2) | 2020.08.12 |



